
언리얼 엔진에서는 다양한 경로를 사용하여 스켈레탈 메시를 렌더링합니다. 이 페이지에서는 이러한 다양한 경로에 대해 알아보고 프로젝트에서 이를 사용하는 방법을 살펴봅니다.
스켈레탈 메시 렌더링 방법
스켈레탈 메시는 다음과 같은 세 가지 경로를 통해 렌더링됩니다.
섹션 및 청크
스켈레탈 메시는 두 가지 방식, 즉 섹션 또는 청크 로 나뉩니다. 스켈레탈 메시의 각 섹션은 머티리얼과 연관되어 있습니다. 한 섹션의 지오메트리가 많이 복잡하다는 것은 섹션 버텍스에 영향을 미치는 본이 그만큼 많다는 뜻이고, 이 경우 섹션은 지오메트리 파이프라인에 의해 청크로 나뉘어지고 이는 메시가 생성하는 드로 콜의 숫자도 많아지는 결과로 이어집니다.
스켈레탈 메시 에디터에서 스켈레탈 메시 에셋을 살펴볼 때 디테일(Details) 패널을 보면 메시의 머티리얼이 어떻게 나뉘어져 있는지 확인할 수 있습니다. 각 LOD 카테고리에서 섹션(Sections) 을 확장하면 머티리얼과 청크의 목록을 확인할 수 있습니다.
아래에는 두 가지 예시가 나와 있습니다. 첫 번째는 가장 일반적인 결과로, 각 스켈레탈 메시와 LOD의 머티리얼 또는 섹션의 목록을 보여줍니다. 두 번째에서는 보다 세분화된 정보를 확인할 수 있는데, 섹션(1)이 청크(2)로 나뉜 것을 알 수 있습니다. 일반적으로, 스켈레탈 메시 에디터의 섹션은 머티리얼에 매핑됩니다. 런타임에서 렌더링 코드의 섹션은 청크를 참조합니다.
 |
 |
|---|---|
| 머티리얼 섹션만 있는 스켈레탈 메시 에셋 | 섹션(1)과 청크(2)가 있는 스켈레탈 메시 에셋 |
8비트 및 16비트 본 인덱스
스켈레탈 메시를 임포트하는 경우 이러한 스켈레탈 메시는 섹션을 지원할 수 있는 본이 얼마나 많은지 설정하는 8비트 또는 16비트 본 인덱스를 가질 수 있습니다. 8비트 본 인덱스는 섹션당 최대 256개의 본을 지원하며, 16비트 본 인덱스는 256개 이상의 본을 지원합니다.
기본적으로 모든 메시는 8비트 본 인덱스를 사용하여 임포트됩니다. 엔진(Engine) > 렌더링(Rendering) > 스키닝(Skinning) 의 프로젝트 세팅 에서 16비트 본 인덱스 지원(Support 16-bit Bone Index) 체크 상자를 선택하면 섹션당 더 많은 본을 지원할 수 있습니다.

이 세팅을 활성화하려면 다음을 수행합니다.
- 이 변경사항을 적용할 수 있도록 에디터를 다시 시작해야 합니다.
- 이러한 변경사항이 적용되기 전에 스켈레탈 메시가 이미 프로젝트에 있다면 업데이트될 수 있도록 다시 임포트 해야 합니다.
- 임포트된 스켈레탈 메시는 섹션이 최대 256개의 본 또는 그 이상을 가지고 있는지에 따라 8비트 또는 16비트를 사용합니다.
섹션당 최대 본
스켈레탈 메시는 임포트되는 소스 메시에 대해 섹션당 본의 최대 한도를 허용합니다. 섹션당 허용되는 본의 수는 단일 드로 콜에서 GPU에 스키닝될 수 있는 본의 수입니다. 소스 메시가 섹션당 본의 최대 한도를 넘는 경우 지오메트리 파이프라인은 한도 내에 해당하는 더 작은 청크로 섹션을 나눕니다.
섹션당 본의 최대 수를 제어하는 일반적인 사용 사례는 프로젝트가 하이 엔드 및 모바일 플랫폼을 모두 지원하는 경우입니다. 프로젝트 세팅 을 사용하여 모든 플랫폼의 섹션당 최대 본(Maximum bones per Sections) 을 설정하거나 엔진 > 렌더링 > 스키닝 에서 개별 플랫폼을 설정할 수 있습니다.
기본적으로 섹션당 최대 본은 65,536개로 설정되어 있습니다. 모바일 플랫폼은 섹션당 최대 75개의 본으로 제한됩니다.

+ 모양의 추가(Add) 아이콘을 클릭하고 목록에서 플랫폼을 선택하여 이 세팅을 플랫폼별로 오버라이드할 수 있습니다.

플랫폼별 세팅은 글로벌 세팅 Compat.MAX_GPUSKIN_Bones 으로 제한되어 있습니다. 기본적으로 이는 65,536개로 설정되어 있으며 이 값을 초과해서는 안 됩니다. 16비트 인덱스 모드가 활성화되어 있지 않은 경우 이 한도는 256개로 제한되거나 8비트 본 인덱스로 제한됩니다.
콘솔 명령어 SkeletalMeshReport 를 사용하면 프로젝트의 각 스켈레탈 메시를 분석하는 통계 로그를 출력할 수 있습니다. 분석 정보에는 구성 및 메모리 사용량에 대한 정보가 포함됩니다.

GPU 스킨 버텍스 팩토리
GPU 스킨 버텍스 팩토리 는 버텍스 셰이더를 사용하여 위치와 노멀/탄젠트를 스키닝하며 필요에 따라 결과가 GPU에 저장됩니다. 각 버텍스 팩토리는 디폴트 본 인플루언스 와 무제한 본 인플루언스 를 모두 지원합니다.
디폴트 본 인플루언스는 각 버텍스가 4개 또는 8개의 본 인플루언스에 의해 스키닝될 수 있는지 여부를 제어합니다. 본 인플루언스의 수는 스켈레탈 메시가 버텍스당 4개의 본으로 렌더링되는 경우 이와 같이 고정되며 버텍스가 오직 하나의 본만 사용하는 경우에는 남은 세 개의 슬롯에 웨이트가 채워지지 않고 스키닝 계산에 사용됩니다. 본 인덱스와 웨이트는 버텍스 스트림에 바인딩되어 이 모드가 로우 엔드 하드웨어 및 플랫폼에 적합하도록 만들어줍니다.
무제한 인플루언스는 버텍스당 고정된 수의 본 인플루언스 제한을 해제하여 다양한 수의 본 인플루언스가 대신 사용될 수 있도록 해줍니다. 본 인덱스/웨이트가 버텍스 스트림에 직접 바인딩되는 대신 각 버텍스가 인덱스 오프셋을 저장하고 본 인플루언스 수를 하나의 인티저로 묶습니다. 이 값은 본 인덱스와 웨이트 데이터를 포함하고 있는 버텍스 버퍼를 조회하기 위해 사용됩니다.
무제한 본 인플루언스 모드 활성화하기
엔진 > 렌더링 > 스키닝 섹션의 프로젝트 세팅 에서 무제한 본 인플루언스 모드를 활성화할 수 있습니다.

다음과 같은 두 가지 세팅은 반드시 설정해야 합니다.
- 무제한 본 인플루언스 사용 은 새로 임포트되거나 다시 임포트된 스켈레탈 메시를 활성화하여 렌더링에 디폴트 최대 본 인플루언스 대신 무제한 본 버퍼를 사용하도록 합니다. 이 세팅은 런타임에서 변경할 수 없으며 이 세팅을 활성화하면 에디터를 재시작해야 합니다.
- 무제한 본 인플루언스 한계치 는 메시의 최대 디폴트 본 인플루언스가 제한을 초과하기 전까지 버퍼 하나당 고정된 본 인플루언스를 사용합니다.
이론상으로 버텍스당 인플루언스의 최대 수는 제한되어 있지 않지만 스켈레탈 메시 소스 데이터가 저장되는 방식으로 인해 실제 인플루언스의 최대 수는 12개로 제한되어 있습니다.
무제한 본 인플루언스 모드를 사용하는 경우 무제한 본 인플루언스 를 활성화하고 무제한 본 인플루언스 한계치 를 8 로 설정하는 것이 권장됩니다. 본 인플루언스가 9에서 12 사이인 스켈레탈 메시는 무제한 본 인플루언스 경로로 렌더링되고, 0에서 8 사이인 본 인플루언스는 고정된 4/8 본 인플루언스 경로로 렌더링됩니다.
스킨 캐시 시스템
스킨 캐시 시스템은 셰이더 계산 을 사용하여 위치와 노멀/탄젠트를 스키닝하며, 결과가 버텍스 버퍼에 캐시된 다음 렌더링을 위해 LocalVertexFactory 의 베리에이션인 GPUSkinPassThroughVertexFactory 으로 전달됩니다.

스킨 캐시 계산 지원(Support Compute Skin Cache) 세팅을 사용하여 엔진 > 렌더링 > 최적화(Optimizations) 섹션의 프로젝트 세팅 에서 스킨 캐시 시스템을 활성화할 수 있습니다.

이 시스템은 프로젝트 수준에서 스캔 캐시 동작을 정의하여 개별 스켈레탈 메시가 이러한 동작을 유연하게 오버라이드할 수 있게 해줍니다.
다음 프로젝트 세팅을 사용하여 스킨 캐시 동작 및 지원을 설정할 수 있습니다.
- 디폴트 스킨 캐시 동작(Default Skin Cache Behavior) 은 스킨 캐시 또는 GPU 스킨 버텍스 팩토리 경로를 통해 이동하는 스켈레탈 메시를 제어합니다. 두 가지 동작을 선택할 수 있습니다.
- 포함(Inclusive) 은 기본적으로 스킨 캐시에 모든 스켈레탈 메시를 포함합니다. 개별 스켈레탈 메시는 사용하지 않도록 설정하고 GPU 스킨 버텍스 팩토리 경로를 대신 사용할 수 있습니다.
- 제외(Exclusive) 는 기본적으로 스킨 캐시에서 모든 스켈레탈 메시를 제외하고 GPU 스킨 버텍스 팩토리를 사용합니다. 개별 스켈레탈 메시는 스킨 캐시를 사용하도록 설정할 수 있습니다.
-
월드별 스킨 캐시 계산 최대 메모리(MB) 는 스킨 캐시 계산이 출력 버텍스 데이터를 생성하고 탄젠트 재계산을 허용하는 월드/씬별 메모리의 최대 양을 메가바이트 단위로 설정합니다. 각 월드는 스켈레탈 메시가 스킨 캐시에 먼저 들어오는 순서에 따라 삽입되는 스킨 캐시 오브젝트를 가집니다.
삽입 순서는 게임에 따라 다릅니다. 스킨 캐시가 가득 찬 경우 다른 스켈레탈 메시를 수용할 수 없으며, 해당 메시는 GPU 스킨 버텍스 팩토리 경로를 통해 이동합니다. 이는 메시가 디테일이 낮은 상위 LOD에서 디테일이 높은 하위 LOD로 전환될 때 레벨 오브 디테일과 관련된 상황이 유발됩니다. 이때 스킨 캐시는 상위 LOD를 언로드하지만 더 높은 메모리 요구 사항으로 인해 하위 LOD는 수용할 수 없게 됩니다.
다음과 같은 콘솔 명령어를 사용할 수 있습니다.
r.SkinCache.Mode는 스킨 캐싱의 활성화 또는 비활성화 여부를 설정합니다. 기본적으로 활성화(1)됩니다.r.SkinCache.SkipCompilingGPUSkinVF는 스킨 캐시 시스템이 활성화되어 있는 경우 셰이더 순열의 컴파일을 건너뛰어 GPU 스킨 버텍스 팩토리 베리언트를 줄여줍니다.- 0 은 모든 GPU 스킨 버텍스 팩토리 베리언트를 컴파일합니다. 디폴트입니다.
- 1 은 모든 GPU 스킨 버텍스 팩토리 셰이더 순열을 컴파일하지 않습니다.
스켈레탈 메시에 스킨 캐시 오버라이드하기
개별 스켈레탈 메시 LOD는 스킨 캐시 사용(Skin Cache Usage) 드롭다운을 선택하여 스킨 캐시 동작을 오버라이드할 수 있습니다.
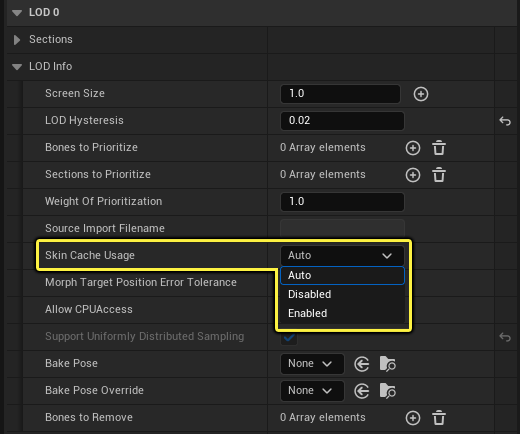
다음 중에서 선택할 수 있습니다.
- 자동(Auto): 디폴트 스킨 캐시 동작을 위한 프로젝트 세팅에서 글로벌 동작 세트를 사용합니다.
- 비활성화(Disabled): 이 메시는 스킨 캐시를 사용하지 않습니다. 하드웨어 레이 트레이싱이 메시에 활성화되어 있다면 스킨 캐시도 활성화됩니다.
- 활성화됨(Enabled): 이 메시는 스킨 캐시를 사용합니다.
레이 트레이싱 및 헤어 스트랜드 스킨 캐시 렌더링 요구 사항
하드웨어 레이 트레이싱 및 헤어 스트랜드 렌더링과 같은 렌더링 기능은 렌더링을 위한 스킨 캐시 경로가 필요합니다. 하지만 스킨 캐시 경로는 디포머 그래프를 사용하여 디스플레이스먼트를 구동하는 경우에는 사용되지 않습니다. 레이 트레이싱 및 헤어 스트랜드 렌더링은 디포머 그래프가 사용되는 경우 항상 작동합니다.
하드웨어 레이 트레이싱을 사용하면 모든 스켈레탈 메시는 자동으로 스킨 캐시 경로를 거치며 레이 트레이싱 이펙트로 렌더링됩니다. r.RayTracing.Geometry.SupportSkeletalMeshes 를 사용하여 하드웨어 레이 트레이싱에 대해 스켈레탈 메시를 비활성화하면 GPU 메모리 및 시간 리소스를 절약할 수 있습니다. 이는 런타임에서 변경할 수 없습니다.
또한 메시는 기존의 래스터 LOD에서 별도의 레이 트레이싱된 LOD를 사용하는 옵션을 제공합니다. 글로벌 레이 트레이싱 LOD 바이어스, 즉 r.RayTracing.Geometry.SkeletalMeshes.LODBias 와 개별 스켈레탈 메시 세팅인 레이 트레이싱 최소 LOD(Ray Tracing Min LOD) 조합을 사용하여 이를 제어할 수 있습니다. 상위 LOD 인덱스는 래스터 LOD 인덱스, 글로벌 레이 트레이싱 LOD 인덱스, 레이 트레이싱 최소 LOD 세트 사이에서 선택됩니다.

탄젠트 재계산
탄젠트 재계산(Recompute Tangents) 은 스키닝 패스 이후의 선택적 스킨 캐시 단계입니다. 스킨 캐시는 스키닝된 트라이앵글을 사용하여 노멀과 탄젠트를 다음과 같은 2개의 셰이더 계산 단계에서 재계산합니다.
- 트라이앵글 패스 - 각 트라이앵글이 스키닝된 버텍스 위치에서 노멀과 탄젠트를 계산하고 세 개의 버텍스에 결과를 누적합니다.
- 버텍스 패스 - 각 버텍스가 누적된 노멀 및 탄젠트를 정규화합니다. 메시의 버텍스 컬러 버퍼 채널 중 하나는 스키닝된 노멀/탄젠트와 재계산한 노멀/탄젠트 사이에서 혼합 마스크로 선택적으로 사용됩니다.
프로젝트에 대해 글로벌로 또는 스켈레탈 메시별로 탄젠트 재계산을 설정할 수 있습니다.
글로벌 세팅:
r.SkinCache.RecomputeTangents- 1 은 모든 스켈레탈 메시에서 탄젠트를 재계산하도록 강제합니다.
- 2 는 해당 섹션에서 탄젠트 재계산을 활성화한 스켈레탈 메시에 대해서만 탄젠트를 재계산합니다. 디폴트입니다.
메시별 세팅:
LOD [n] 카테고리에서 섹션을 사용하여 각 머티리얼 섹션에 탄젠트 재계산이 처리되는 방법을 설정합니다.

선택할 수 있는 옵션은 다음과 같습니다.
- 없음(None): 탄젠트를 재계산하지 않습니다.
- 모두(All): 모든 컬러 채널에 대해 탄젠트를 재계산하고 재계산된 결과를 사용합니다.
- 레드(Red)/그린(Green)/블루(Blue): R/G/B 버텍스 컬러 버퍼 채널을 블렌딩 마스크로 사용하여 스키닝된 결과로 선형보간하고 탄젠트를 재계산합니다.
탄젠트 재계산의 한 가지 제약은 각 청크가 메시의 다른 청크에서 별개로 처리된다는 것입니다. 따라서 인접한 청크와 연결된 청크의 버텍스는 연결을 전혀 인지하지 못합니다. 그 결과로 인해 두 청크의 경계를 따라 육안으로 확인할 수 있는 이음새가 생깁니다.
스킨 캐시 디버깅 팁
다음을 사용하여 프로젝트에서 스킨 캐싱을 디버깅할 수 있습니다.
콘솔 명령
-
profilegpu- 개별 스킨 캐시 항목의 디테일과 속해 있는 스켈레탈 메시와 함께 GPU 프레임을 캡처합니다.
-
r.SkinCache.PrintMemorySummary- 모든 스킨 캐시 항목의 메모리 사용량 분석 정보를 출력합니다.- 0 은 개요를 비활성화합니다. 디폴트입니다.
- 1 은 메모리가
r.SkinCache.SceneMemoryLimitInMB에 의해 설정된 제한 또는 프로젝트 세팅에서 월드별 스킨 캐시 계산 최대 메모리(MB) 를 초과할 경우 프레임에 개요를 프린트합니다. - 2 는 모든 프레임에 개요를 프린트합니다.
스킨 캐시 디버그 시각화
GPU 스킨 캐시(GPU Skin Cache) 목록에서 디버그 시각화 중 하나에 대해 뷰 모드(View Modes) 드롭다운을 사용하여 컬러를 적용해 개별 스켈레탈 메시를 시각화합니다.

-game 명령줄 실행인자를 사용하여 프로젝트를 시작하는 경우 Overview , Memory 또는 RayTracingLODOffset 와 함께 콘솔 명령어 r.SkinCache.Visualize 를 입력하여 이러한 시각화 모드를 사용할 수 있습니다. 시각화는 다음의 None 명령어로 비활성화할 수 있습니다. 이 뷰 모드는 패키징된 빌드에서 비활성화되어 있습니다.
개요 시각화
개요 시각화는 스킨 캐시와 탄젠트 재계산이 활성화 또는 비활성화된 씬에 액터를 표시합니다.

'뷰포트(Viewport)' 왼쪽 상단에는 씬의 액터를 위한 컬러 레퍼런스가 표시됩니다.

메모리 시각화
메모리 시각화는 래스터 및 레이 트레이싱 조합에 대한 스킨 캐시 메모리 사용량을 낮음, 중간, 높음 단계로 보여줍니다.

'뷰포트' 왼쪽 상단에는 스킨 캐시 메모리 정보가 표시됩니다.

DefaultEngine.ini 환경설정 파일의 [/Script/Engine.Engine] 섹션에 있는 GPUSkinCacheVisualizationLowMemoryThresholdInMB 및 GPUSkinCacheVisualizationHighMemoryThresholdInMB 의 값을 편집하여 프로젝트당 메모리 한계치를 오버라이드할 수 있습니다.
레이 트레이싱 LOD 오프셋 시각화
레이 트레이싱 LOD 오프셋 시각화는 레이 트레이싱된 스킨 캐시 항목과 래스터 스킨 캐시 항목 사이의 LOD 인덱스 차이를 보여주므로 레이 트레이싱이 래스터화에 사용되는 경우 별도의 LOD를 사용할 때 유용합니다.

이 시각화 모드는 하드웨어 레이 트레이싱이 프로젝트 세팅에서 활성화되어 있는 경우에만 사용할 수 있습니다.
'뷰포트' 왼쪽 상단에는 씬의 액터를 위한 레이 트레이싱 LOD 오프셋의 컬러 코드가 표시됩니다.

디포머 그래프 플러그인
이 기능은 현재 베타 버전입니다.
디포머 그래프 플러그인은 GPU에서 독점적으로 실행되는 버텍스 디포메이션 파이프라인을 생성할 수 있게 해주는 에디터입니다. 플러그 앤 플레이를 위한 그래프 에디팅 기능을 제공하고 필요한 데이터 플로를 구성하여 수신하는 입력에 따라 메시 버텍스 포인트를 수정합니다.
