
El texto en Unreal Engine (UE) es el componente principal para la localización. Es una cadena especializada, representada por el tipo FText en C++. Debería usarse cuando haya texto visible para el usuario que deba localizarse.
Internamente, FText se implementa como una extensión TSharedRef en una interfaz ITextData. Esto hace que resulte muy económico copiarlo. Además, la instantánea FTextSnapshot permite detectar de forma eficiente si un valor FText almacenado en caché ha cambiado realmente.
Los datos contenidos en las instancias de FText varían en función de cómo se haya creado FText. De esta varianza se encarga el «historial de texto» interno (FTextHistory). Los historiales de texto permiten la reconstrucción del texto en función de la variante correcta y también son el componente clave para lo siguiente:
-
Cambio de variante en tiempo real.
-
Envío de
FTexta través de la red. -
Creación de fuentes invariables de variantes.
Convertir FText a FString suele ser una operación con pérdidas, ya que se pierde el historial de texto. Solo debería hacerse si ya no necesitas los datos de localización. Por ejemplo, si hay una API de nivel inferior que funciona con cadenas y está gestionada por una API de nivel superior que busca cambios en el texto (como STextBlock). Esta conversión también se puede usar al pasar los datos a una API externa que solo acepte cadenas.
Si necesitas texto que no sea localizable (por ejemplo, para convertir el nombre de un jugador de una API externa en algo que puedas mostrar en tu IU), puedes usar FText::AsCultureInvariant, que produce una instancia de FText sin datos de localización (y no se puede localizar). La macro INVTEXT puede hacer lo mismo con cadenas literales.
Literales de texto
El texto localizable se compone de tres componentes: un espacio de nombres, una clave (que forma su identidad) y una cadena de origen (que es la base de lo que se traduce y actúa como validación frente a traducciones «obsoletas»). La forma más común de crear texto localizable en UE es usando un literal de texto.
Creación de literales de texto en C++
Los literales de texto se pueden crear en C++ con la familia de macros LOCTEXT.
Macros de literales de texto
| Macro | Descripción |
|---|---|
| NSLOCTEXT | Crea contenido de texto localizado definiendo el espacio de nombres, la clave y la cadena de origen. |
| LOCTEXT | Crea contenido de texto localizado definiendo la clave y la cadena de origen. El espacio de nombres se define con LOCTEXT_NAMESPACE. |
Ejemplo:
// Define el espacio de nombres que se quiere usar con LOCTEXT
// Esto solo es válido dentro de un único archivo y debe estar indefinido antes del final del archivo
#define LOCTEXT_NAMESPACE "MyNamespace"
// Crea literales de texto
constFTextHelloWorld= NSLOCTEXT("MyOtherNamespace","HelloWorld","Hello World!")
constFTextGoodbyeWorld= LOCTEXT("GoodbyeWorld","Goodbye World!")
// Anula la definición del espacio de nombres antes del final del archivo
#undef LOCTEXT_NAMESPACE
Creación de literales de texto en archivos INI
Los literales de texto se pueden crear en archivos INI con la sintaxis de macros NSLOCTEXT .
Creación de literales de texto en los recursos
Los literales de texto se pueden crear usando las propiedades FText. Se generará una clave para ti automáticamente, pero puedes definir un espacio de nombres o una clave personalizada para el texto usando el menú combinado avanzado que hay junto al campo de texto. También puedes usar el espacio de nombres o la clave predeterminados.
Formato de texto
El formato de texto permite combinar texto para que sea más fácil de localizar mediante un patrón de formato localizable que inyecta texto real para reemplazar los marcadores de posición de formato.
Los marcadores de posición de formato aparecen entre llaves y pueden ser números (para el formato basado en índices) o cadenas (para el formato basado en nombres). Por ejemplo:
«Te quedan {0} de salud.»
«Te quedan {CurrentHealth} de salud.»
Los marcadores de posición de formato también pueden especificar una función (llamada « modificador de argumento») que se ejecutará en sus datos de argumento. Se especifican como una canalización seguida del nombre de la función y sus argumentos. Por ejemplo:
"{NumCats} {NumCats}|plural(one=cat,other=cats)"
Puedes usar el carácter de barra diagonal invertida (`) para escapar las llaves y barras verticales, y evitar que se consideren marcas de formato. También puedes usar la barra diagonal invertida como escape de sí misma y producir un carácter literal `.
Ejemplo:
La siguiente tabla asume que el valor de Res es un entero cuyo valor es 10.
| Entrada | Resultado de texto con formato |
|---|---|
|
|
|
|
Formato de texto en C++
El formato de texto en C++ lo gestiona la familia de funciones FText::Format . Cada función ocupa un patrón de FTextFormat que implícitamente se construirá a partir de una instancia de FText, seguida de argumentos adicionales, tal y como se define en la tabla de abajo.
| Argumento | Tipo de formato | Descripción |
|---|---|---|
| FText::Format | Formato general de texto. | Acepta argumentos basados en índices (usando FFormatOrderedArguments o argumentos variádicos) o argumentos basados en nombres (con FFormatNamedArguments). |
| FText::FormatOrdered | Formato variádico basado en índices. | Acepta los argumentos a partir de los cuales puede construir FFormatArgumentValue. |
| FText::FormatNamed | Formato variádico basado en nombres. | Acepta argumentos consecutivos de nombre (cualquier elemento a partir del cual FString se pueda construir) y luego de valor (cualquier elemento a partir del cual se pueda construir FFormatArgumentValue). |
Deberías plantearte precompilar los patrones de formato que usas con frecuencia en un FTextFormat para mejorar el rendimiento formato. El patrón compilado se recompilará automáticamente si cambia la referencia de variante activa.
Formato de texto en blueprints
El nodo Format Text se encarga del formato de texto en los blueprints. Este nodo puede adoptar un patrón de formato literal o puede tener el patrón vinculado a otro pin de texto.
-
Cuando se especifica un patrón de formato literal, los pines de argumentos de formato se generan automáticamente.
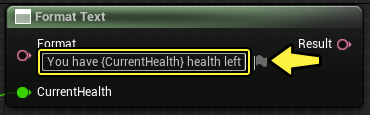
-
Cuando el patrón de formato está vinculado a otro pin de texto, debes especificar manualmente los argumentos para el formato en el panel Detalles del nodo.
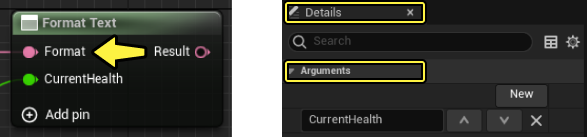
Modificadores de argumentos
Los modificadores de argumentos permiten preprocesar un argumento antes de que se añada a la cadena con formato. Los modificadores de argumentos son ampliables. Un modificador de argumento se crea implementando la interfaz ITextFormatArgumentModifier y registrando después una función de fábrica para una palabra clave determinada (consulta FTextFormatter::RegisterTextArgumentModifier).
UE proporciona algunos modificadores de argumento por defecto: hay modificadores de número, de género y posposiciones en el hangul.
Formas de número
Las formas de número te permiten usar texto distinto en función de una variable numérica asignada a tu formato de texto. Las formas de número pueden ser cardinales (por ejemplo, «Hay 1 gato» o «Hay 4 gatos») u ordinales (por ejemplo, «¡Terminaste en primer lugar!» o «¡Terminaste en segundo lugar!). Las formas de número se especifican como pares clave-valor y son compatibles con cualquiera de las siguientes palabras clave (tal y como se definen para tu variante por los datos CLDR): cero, uno, dos, pocos, muchos, otro. Los valores son cadenas entre comillas opcionales que también pueden contener marcadores de formato.
Ejemplo de formato cardinal:
«Hay {NumCats}|plural(one=is,other=are) {NumCats} {NumCats}|plural(one=cat,other=cats)»
Ejemplo de formato ordinal:
«¡Has llegado el {Place}{Place}|ordinal(one=st,two=nd,few=rd,other=th)!»
Formas de género
Las formas de género te permiten usar texto distinto en función de un valor de ETextGender dado al formato del texto, como el ejemplo «Le guerrier est fort» o «La guerrière est forte». Las formas de género se especifican como una lista de valores en el orden de [masculino, femenino, neutro], donde el neutro es opcional. Los valores son cadenas opcionales entre comillas que también pueden contener marcadores de formato.
Ejemplo de formato:
«{Gender}|gender(Le,La) {Gender}|gender(guerrier,guerrière) est {Gender}|gender(fort,forte)»
Posposiciones en el hangul
Las posposiciones en el hangul te ayudan a seguir las reglas gramaticales presentes en el coreano e insertarán los glifos correctos en función de si el valor que se está insertando termina en consonante o vocal, como «사람은» o «사자는». Las posposiciones en el hangul se especifican como una lista de valores en el orden [consonante, vocal]. Los valores son una cadena entre comillas opcionales.
Ejemplo de formato:
«{Arg}|hpp(은,는)»
Prácticas recomendadas para el formato de texto
-
Cuando inyectes un número que afecte a la frase, maneja estas varianzas usando los modificadores de argumento de número en lugar de hacerlo con ramificación en el código. Cuando usas formas de número, la oración se traduce correctamente para idiomas que no comparten las reglas de plural de tu idioma de origen.
-
Si inyectas nombre personal, asegúrate de incluir un argumento para el género de la persona. Esto es importante para los idiomas con reglas gramaticales para el género, ya que permite a los traductores cambiar la traducción en función del género (consulta Formas de género).
-
Si inyectas nombres a objetos (como «mesa», «puerta» o «silla»), recuerda que deben ir con concordancia de género. Estos nombres pueden tener un género en un idioma y otro distinto en otro. Esto hace que la cadena del patrón de formato sea imposible de localizar con precisión sin metadatos específicos de la variante. Lo ideal sería incluir frases completas en lugar de solo el sustantivo. Esto garantiza que las traducciones sean precisas.
Futuras versiones de UE podrían incluir una función para que los traductores usen metadatos para etiquetar texto que represente sustantivos que luego puedan ramificar en patrones de formato para obtener traducciones precisas.
-
Evita la concatenación de frases parciales. Esto puede causar problemas, ya que es posible que cada cláusula o parte se traduzca correctamente y, sin embargo, la traducción completa podría ser incorrecta. Es mejor reescribir el texto en frases completas para garantizar de que la traducción es correcta.
Generación de texto
La generación de texto usa datos de internacionalización para producir texto con variantes correctas que no dependa de la localización directa. Hay tres tipos de generación de texto: numérica, cronológica y transformativa.
Generación numérica de texto
La generación numérica se usa para convertir tipos numéricos en una representación de texto fácil de leer para los humanos. Las reglas exactas son específicas de la variante y también pueden modificarse por generación si se requiere un control más específico.
Por ejemplo, con las reglas de generación predeterminadas, el número de coma flotante «1234.5» se generaría como «1,234.5» en inglés, «1 234,5» en francés y «١٬٢٣٤٫٥» en árabe.
Generación numérica en C++
La generación numérica en C++ se gestiona con las siguientes funciones.
| Función | Descripción |
|---|---|
| FText::AsNumber | Convierte cualquier tipo de número compatible con UE en una representación de texto fácil de usar («1234.5» pasa a ser «1,234.5»). |
| FText::AsPercent | Convierte un valor flotante o doble en una representación de texto en porcentaje («0,2» pasa a ser «20 %»). |
| FText::AsMemory | Convierte un valor (en bytes) en una representación de memoria fácil de usar («1234» se convierte en «1.2 KiB»). |
| FText::AsCurrencyBase | Convierte un valor de la representación base de una moneda en una representación de moneda sencilla («1234.50» para «USD» se convierte en «$1,234.50»). |
La mayoría de las funciones de la tabla utilizan una clase opcional [FNumberFormattingOptions](https://api.unrealengine.com/INT/API/Runtime/Core/Internationalization/FNumberFormattingOptions/index.html) para controlar la salida (por defecto, tomada de la configuración regional activa) y también una variante opcional (por defecto, la configuración regional activa).
Generación numérica en blueprints
La generación numérica en blueprints se gestiona en los siguientes nodos.
| Nodos | Descripción |
|---|---|
| ToText (byte), ToText (integer), ToText (float) | Convierte los tipos numéricos compatibles con UE en una representación de texto fácil de usar («1234.5» pasa a ser «1,234.5»). |
| AsPercent | Convierte un valor flotante o doble en una representación de texto en porcentaje («0,2» pasa a ser «20 %»). |
| AsCurrency | Convierte un valor de la representación base de una moneda en una representación de moneda sencilla («1234.50» para «USD» se convierte en «$1,234.50»). |
La mayoría de los nodos de la tabla toman argumentos avanzados para controlar la salida.
Generación cronológica
La generación cronológica se usa para convertir tipos de fecha y hora en una representación de texto fácil de leer para los humanos. Las reglas exactas son específicas de la variante, y el estilo de fecha y hora se puede ajustar por generación si se requiere un control más específico.
Según las reglas de generación predeterminadas, una fecha que represente el día 22 del quinto mes del año 1998 generaría «May 22, 1998» en inglés (Estados Unidos), «22 May 1998» en inglés (Reino Unido), «22 may 1998» en francés y «٢٢/٠٥/١٩٩٨» en árabe.
Generación cronológica en C++
La generación cronológica en C++ se gestiona con las siguientes funciones.
| Función | Descripción |
|---|---|
| FText::AsDate | Convierte un valor de FDateTime en una representación de fecha fácil de usar. |
| FText::AsTime | Convierte un valor de FDateTime en una representación de hora fácil de usar. |
| FText::AsDateTime | Convierte un valor de FDateTime en una representación de fecha y hora fácil de usar. |
| FText::AsTimespan | Convierte un valor de FTimespan en una representación de tiempo delta fácil de usar (en horas, minutos y segundos). |
La mayoría de los anteriores usan EDateTimeStyle para controlar la salida (por defecto, se toma de la configuración regional activa, pero puede definirse como «corto», «medio», «largo» o «completo»).
La generación de tiempo espera que se le asigne una hora basada en UTC por defecto (la cual se convertirá a la zona horaria local). Si la hora indicada no está basada en UTC (por ejemplo, si ya estuviera en horario local), deberías pasar [FText::GetInvariantTimeZone()](https://api.unrealengine.com/INT/API/Runtime /Core/Internationalization/FText/GetInvariantTimeZone/index.html) como argumento de la zona horaria.
Generación cronológica en blueprints
La generación cronológica en blueprints se gestiona en los siguientes nodos.
| Nodos | Descripción |
|---|---|
| AsDate | Convierte un valor de fecha y hora que no esté basado en UTC en una representación de fecha fácil de usar tal cual (sin ajustar la zona horaria local). |
| AsDate (from UTC) | Convierte un valor de fecha y hora basado en UTC en una representación de fecha fácil de usar (que se ajusta a la zona horaria local). |
| AsTime | Convierte un valor de fecha y hora que no esté basado en UTC en una representación de hora fácil de usar tal cual (sin ajustar la zona horaria local). |
| AsTime (from UTC) | Convierte un valor de fecha y hora basado en UTC en una representación de hora fácil de usar (que se ajusta a la zona horaria local). |
| AsDateTime | Convierte un valor de fecha y hora que no esté basado en UTC en una representación de fecha y hora fácil de usar tal cual (sin ajustar la zona horaria local). |
| AsDateTime (from UTC) | Convierte un valor de fecha y hora basado en UTC en una representación de fecha y hora fácil de usar (que se ajusta a la zona horaria local). |
| AsTimespan | Convierte un valor de Timespan en una representación de tiempo delta fácil de usar (en horas, minutos y segundos). |
Generación transformativa
La generación transformativa se usa para convertir texto en una representación distinta de sí mismo. Por ejemplo, puedes convertir texto en minúsculas a texto en mayúsculas o convertir texto en mayúsculas a texto en minúsculas.
Generación transformativa en C++
La generación transformativa en C++ se gestiona con las siguientes funciones.
| Función | Descripción |
|---|---|
| FText::ToLower | Convierte una instancia de FText a minúsculas de forma compatible con Unicode. |
| FText::ToUpper | Convierte una instancia de FText a mayúsculas de forma compatible con Unicode. |
Generación transformativa en blueprints
La generación transformativa en blueprints se gestiona en los siguientes nodos.
| Nodo | Descripción |
|---|---|
| Text to Lower | Convierte una instancia de Text a minúsculas de forma compatible con Unicode. |
| Text to Upper | Convierte una instancia de Text a mayúsculas de forma compatible con Unicode. |
Tablas de cadenas
Las tablas de cadenas permiten centralizar el texto localizado en una (o varias) ubicaciones conocidas y, a continuación, hacer referencia a las entradas de una tabla de cadenas desde otros recursos o código de una forma robusta que permita reutilizar fácilmente el texto localizado.
Las tablas de cadenas pueden definirse en C++, cargarse con un archivo CSV o crearse como recurso. Consulta la página Tablas de cadenas para obtener más información.
Control de los valores de texto
Los valores de texto se pueden controlar sin pérdidas como cadenas (usando FTextStringHelper o [ImportText] (https://api.unrealengine.com/INT/API/Runtime/CoreUObject/UObject/UScriptStruct/ImportText/index.html) y las funciones ExportText de UTextProperty).
Se admiten los siguientes formatos:
| Literal de texto | Descripción | | --- | --- | |NSLOCTEXT | Un literal de texto que especifica el espacio de nombres, la clave y la cadena de origen. |
| LOCTEXT | Un literal de texto que especifica la clave y la cadena origen. |
| LOCTABLE | Una referencia de la tabla de cadenas. |
| INVTEXT | Un contenido de texto que no cambia la variante (consulta FText::AsCultureInvariant). |
| LOCGEN_NUMBER | Un contenido de texto generado a partir de un número (consulta FText::AsNumber). |
| LOCGEN_NUMBER_GROUPED | Un contenido de texto generado a partir de un número con la agrupación habilitada (consulta FText::AsNumber y FNumberFormattingOptions::DefaultWithGrouping). |
| LOCGEN_NUMBER_UNGROUPED | Un contenido de texto generado a partir de un número con la agrupación deshabilitada (consulta FText::AsNumber y FNumberFormattingOptions::DefaultNoGrouping). |
| LOCGEN_NUMBER_CUSTOM | Un contenido de texto generado a partir de un número con opciones de formato personalizado (consulta FText::AsNumber y FNumberFormattingOptions). |
| LOCGEN_PERCENT | Un contenido de texto generado a partir de un número expresado como porcentaje (consulta FText::AsPercent). |
| LOCGEN_PERCENT_GROUPED | contenido de texto generado a partir de un número expresado como porcentaje con la agrupación activada (consulta FText::AsPercent y `FNumberFormattingOptions::DefaultWithGrouping). |
LOCGEN_PERCENT_UNGROUPED |
Contenido de texto generado a partir de un número expresado como porcentaje con la agrupación deshabilitada (consulta FText::AsPercent y FNumberFormattingOptions::DefaultNoGrouping). |
LOCGEN_PERCENT_CUSTOM |
Un contenido de texto generado a partir de un número expresado como porcentaje con opciones de formato personalizado (consulta FText::AsPercent y FNumberFormattingOptions). |
LOCGEN_CURRENCY |
Un contenido de texto generado a partir de un número como moneda (consulta FText::AsCurrencyBase). |
LOCGEN_DATE_UTC |
Un contenido de texto generado a partir de una fecha UTC ajustada a la zona horaria especificada o local (consulta FText::AsDate). |
LOCGEN_DATE_LOCAL |
Un contenido de texto generado a partir de una fecha que no sea UTC y sin ajuste de zona horaria (consulta FText::AsDate). |
LOCGEN_TIME_UTC |
Un contenido de texto generado a partir de una hora UTC ajustada a la zona horaria especificada o local (consulta FText::AsTime). |
LOCGEN_TIME_LOCAL |
Un contenido de texto generado a partir de una hora no UTC sin ajuste de zona horaria (consulta FText::AsTime). |
LOCGEN_DATETIME_UTC |
Un contenido de texto generado a partir de una fecha y hora UTC ajustadas a la zona horaria especificada o local (consulta FText::AsDateTime). |
LOCGEN_DATETIME_LOCAL |
Un contenido de texto generado a partir de una fecha y hora no UTC sin ajuste de zona horaria (consulta FText::AsDateTime). |
LOCGEN_TOLOWER |
Un contenido de texto convertido a minúsculas de forma compatible con Unicode (consulta FText::ToLower). |
LOCGEN_TOUPPER |
Un contenido de texto convertido a mayúsculas de forma compatible con Unicode (consulta FText::ToUpper). |
LOCGEN_FORMAT_ORDERED |
Un contenido de texto generado a partir de un patrón de formato con argumentos basados en índices (consulta FText::FormatOrdered). |
LOCGEN_FORMAT_NAMED |
Un contenido de texto generado a partir de un patrón de formato con argumentos basados en nombres (consulta FText::FormatNamed). |
Las cadenas «sin procesar» también se pueden importar, pero se generará una nueva clave para cada importación. Esto produce claves inestables para la localización.
Tablas de datos
Una causa habitual de la inestabilidad de las claves de localización es la importación iterativa de cadenas sin procesar de un archivo CSV a una tabla de datos, ya que genera una nuevas claves tras cada importación. Una solución para esto es asignar al texto importado una clave determinista después de la importación anulando la función OnPostDataImport en tu estructura de filas y llamando a FText::ChangeKey para asignar la nueva clave.
Normalmente, se usa el nombre de la tabla de datos como espacio de nombres y una combinación del nombre de la fila y el nombre de la propiedad como clave. Por ejemplo:
voidFMyTableRow::OnPostDataImport(constUDataTable*InDataTable,constFNameInRowName,TArray&OutCollectedImportProblems)
{
#if WITH_EDITOR
MyTextProperty = FText::ChangeKey(
InDataTable->GetName(),
FString::Printf(TEXT("%s_%s"),*InRowName.ToString(), GET_MEMBER_NAME_STRING_CHECKED(FMyTableRow,MyTextProperty)),
MyTextProperty
);
#endif// WITH_EDITOR
}
Desde la versión 4.22, ya se aplican claves deterministas a cualquier cadena sin procesar importada a una tabla de datos, pero puedes anular OnPostDataImport si necesitas un comportamiento de codificación personalizado.
Datos políglotas
Los datos políglotas permiten añadir nuevos datos de localización en tiempo de ejecución, ya sea para interactuar con un sistema externo o para permitir correcciones en caliente de la localización sin tener que crear nuevos archivos LocRes.
Los datos políglota se componen de: un espacio de nombres y una clave (su identidad); una cadena nativa; la categoría del texto (por ejemplo, juego, motor o editor) para controlar cuándo se usan los datos políglotas; una variante de origen opcional (que recurrirá a la variante de origen de la categoría si no se configura); y una serie de traducciones por variante.
Si quieres usar datos políglotas para anular una traducción existente, debes garantizar que el espacio de nombres, la clave y la cadena nativa de los datos políglotas coincidan con los del texto de origen que pretendes reemplazar.
Datos políglotas en C++
Los datos políglotas en C++ se representan con el tipo FPolyglotTextData y pueden usarse directamente (usando FPolyglotTextData::GetText para resolver los datos políglotas en una instancia de texto ) o pasarse a FTextLocalizationManager::RegisterPolyglotTextData (para parchear entradas de texto existentes).
Datos políglotas en blueprints
Los datos políglotas en blueprints se representan con el tipo Datos de texto políglota y pueden usarse con la función Datos políglotas a texto para convertir los datos políglotas en una instancia de texto.
Fuentes de texto localizado
Las fuentes de texto localizado son la principal forma en que el gestor de localización de texto de UE descubre y procesa datos de texto localizado. UE proporciona dos por defecto: FLocalizationResourceTextSource (que aloja la compatibilidad con LocRes) y FPolyglotTextSource (que aloja la compatibilidad con datos políglotas).
Las fuentes de texto localizadas pueden proporcionar una forma de interactuar con un sistema externo y pueden añadirse proyecto por proyecto creando y registrando un tipo derivado de ILocalizedTextSource.